One of the micro services we have at work is responsible for converting HTML to PDF. We use wkhtmltopdf to convert HTML to PDF. In my opinion, it is not the nicest tool to use but it is open source and free. In this post, I will show how we use it.
Firstly, we need to download wkhtmltopdf from here. Once installed, copy the wkhtmltopdf.exe from the installed location and paste it in your project directory. Make sure CopyToOutputDirectory is set to Copy always.
Next, since wkhtmltopdf is a command line tool, we will need to run it as a process. The following method shows how we run it
public static Stream BuildFromHtml(string html)
{
Process process;
StreamWriter stdin;
const string fileName = "wkhtmltopdf";
ProcessStartInfo psi = new ProcessStartInfo
{
FileName = fileName,
WorkingDirectory = AppDomain.CurrentDomain.BaseDirectory,
UseShellExecute = false,
CreateNoWindow = true,
RedirectStandardInput = true,
RedirectStandardOutput = true,
RedirectStandardError = true,
Arguments = "-q -n - -" // This will tell wkhtmltopdf to be quiet and not run scripts
};
process = Process.Start(psi);
var pdfStream = new MemoryStream();
try
{
stdin = process.StandardInput;
stdin.AutoFlush = true;
stdin.Write(html);
stdin.Dispose();
CopyStream(process.StandardOutput.BaseStream, pdfStream);
process.StandardOutput.Close();
process.WaitForExit(10000);
pdfStream.Position = 0;
}
catch (Exception ex)
{
Console.WriteLine($"Failed to build pdf from html. {ex.Message}");
throw;
}
finally
{
process.Dispose();
}
return pdfStream;
}
public static void CopyStream(Stream input, Stream output)
{
var buffer = new byte[32768];
int read;
while ((read = input.Read(buffer, 0, buffer.Length)) > 0)
{
output.Write(buffer, 0, read);
}
}Let’s test this with the following HTML
<!DOCTYPE html>
<html lang="en">
<meta charset="UTF-8">
<body>
<div class="">
<h1>This is a Heading</h1>
<p>This is a paragraph.</p>
</div>
</body>
</html> static void Main(string[] args)
{
var html = "<!DOCTYPE html><html lang=\"en\"><meta charset=\"UTF-8\"><body><div class=\"\"><h1>This is a Heading</h1><p>This is a paragraph.</p></div></body></html>";
var pdf = BuildFromHtml(html);
using var fileStream = File.Create($"C:\\Temp\\ConvertedPdf-{DateTime.Now.Ticks}.pdf");
pdf.Seek(0, SeekOrigin.Begin);
pdf.CopyTo(fileStream);
Console.ReadLine();
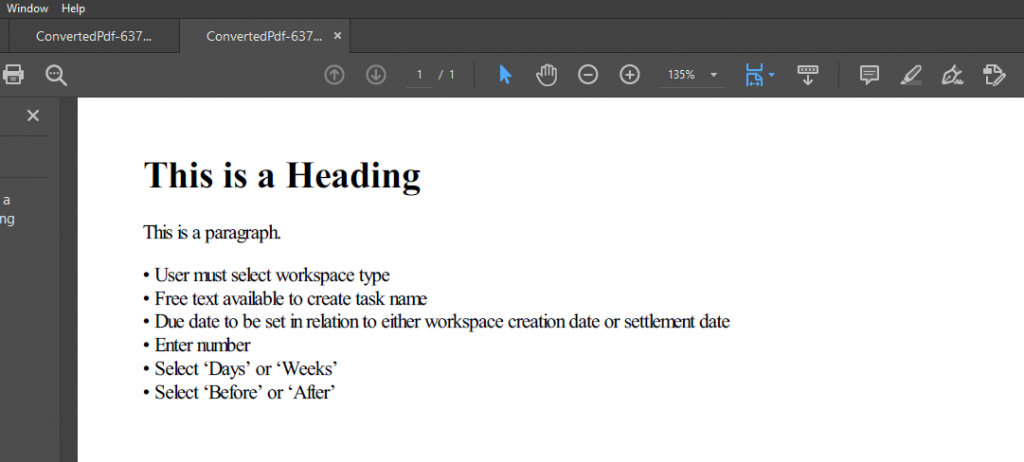
}This is what we would get.
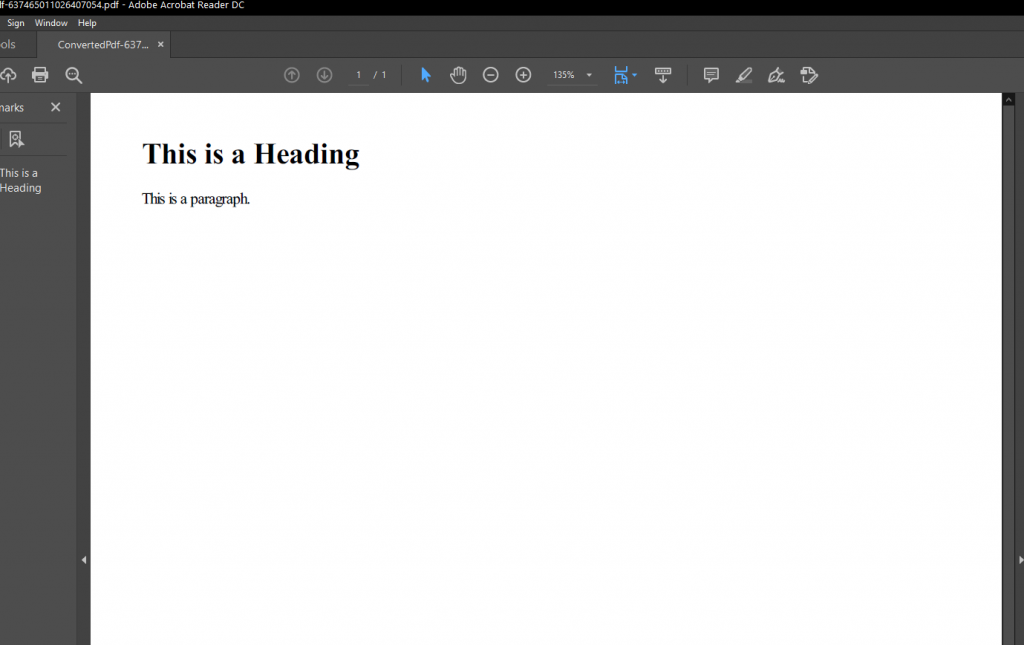
We recently get reports from our testers that the rendered HTML contains strange characters when they paste text containing bullet points and curly quote (‘) from MS Word.

After a lot of investigation, the solution to this was actually simple. We need to set the StandardInputEncoding to Encoding.UTF8 from the ProcessStartInfo. It should look like this.
ProcessStartInfo psi = new ProcessStartInfo
{
FileName = fileName,
StandardInputEncoding = Encoding.UTF8,
WorkingDirectory = AppDomain.CurrentDomain.BaseDirectory,
UseShellExecute = false,
CreateNoWindow = true,
RedirectStandardInput = true,
RedirectStandardOutput = true,
RedirectStandardError = true,
Arguments = "-q -n - -" // note: that we tell wkhtmltopdf to be quiet and not run scripts
};This is the result.